digital-restaurant
DDD. Event sourcing. CQRS. REST. Modular. Microservices. Kotlin. Spring. Axon platform. Apache Kafka. RabbitMQ
Domain
:octocat: /drestaurant-libs :octocat:
This layer contains information about the domain. This is the heart of the business software. The state of business objects is held here. Persistence of the business objects and possibly their state is delegated to the infrastructure layer.
Business capabilities of ‘Digital Restaurant’ include:
- Courier component
- Managing courier information
- A courier view of an order (managing the delivery of orders)
- Restaurant component
- Managing restaurant menus and other information including location and opening hours
- A restaurant view of an order (managing the preparation of orders at a restaurant kitchen)
- Customer component
- Managing information about customers/consumers
- A customer view of an order (managing the order-customer invariants, e.g order limits)
- Order component
- Order taking and fulfillment management
- Accounting component
- Consumer accounting - managing billing of consumers
- Restaurant accounting - managing payments to restaurants
- Courier accounting - managing payments to couriers
As you try to model a larger domain, it gets progressively harder to build a single unified model for the entire enterprise. In such a model, there would be, for example, a single definition of each business entity such as customer, order etc. The problem with this kind of modeling is that:
- getting different parts of an organization to agree on a single unified model is a monumental task.
- from the perspective of a given part of the organization, the model is overly complex for their needs.
- the domain model can be confusing since different parts of the organization might use either the same term for different concepts or different terms for the same concept.
Domain-driven design (DDD) avoids these problems by defining a separate domain model for each subdomain/component.
Subdomains are identified using the same approach as identifying business capabilities: analyze the business and identify the different areas of expertise. The end result is very likely to be subdomains that are similar to the business capabilities. Each sub-domain model belongs to exactly one bounded context.
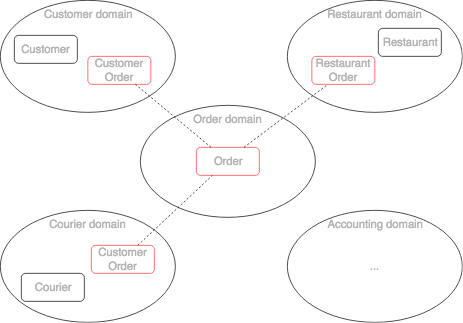
Core subdomains
Some sub-domains are more important to the business then others. This are the subdomains that you want your most experienced people working on. Those are core subdomains:
The Order (RestaurantOrder, CustomerOrder, CourierOrder) aggregate class in each subdomain model represent different term of the same ‘Order’ business concept.
-
The Restaurant component has a simpler view of an order aggregate (RestaurantOrder). Its version of an Order simply consist of a status and a list of line item, which tell the restaurant what to prepare. Additionally, we use event-driven mechanism called sagas to manage invariants between Restaurant aggregate and RestaurantOrder aggregate (e.g. Restaurant order should have only menu items that are on the Restaurant menu)
-
The Courier component has a different view of an order aggregate (CourierOrder). Its version of an Order simply consist of a status and a address, which tell the courier how and where to deliver the order. Additionally, we use saga to manage invariants between Courier aggregate and CourierOrder aggregate (e.g. Courier can deliver a limited number of orders)
-
The Customer component has a different view of an order aggregate (CustomerOrder). Its version of an Order simply consist of a status and a address, which tell the courier how and where to deliver the order. Additionally, we use saga to manage invariants between Customer aggregate and CustomerOrder aggregate (e.g. Customer has an order limit)
-
We must maintain consistency between these different ‘order’ aggregates in different components/domains. For example, once the Order component has initiated order creation it must trigger the creation of RestaurantOrder in the Restaurant component. We will maintain consistency between components/bounded-context using sagas.

Event sourcing
We use event sourcing to persist our event sourced aggregates as a sequence of events. Each event represents a state change of the aggregate. An application rebuild the current state of an aggregate by replaying the events.
Event sourcing has several important benefits:
- It preserves the history of aggregates (100%), which is valuable for auditing and regulatory purposes
- It reliably publishes domain events, which is particularly useful in a microservice architecture.
- You can use any database technology to store the state.
Event sourcing also has drawbacks:
- There is a learning curve because its a different way to write your business logic.
- Events will change shape over time.
- Querying the event store is often difficult, which forces you to use the Command Query Responsibility Segragation (CQRS) pattern.
Consider using event sourcing within ‘core subdomain’ only!
Snapshoting
By use of evensourcing pattern the application rebuild the current state of an aggregate by replaying the events. This can be bad for performances if you have a long living aggregate that is replayed by big amount of events.
- A Snapshot is a denormalization of the current state of an aggregate at a given point in time
- It represents the state when all events to that point in time have been replayed
- They are used as a heuristic to prevent the need to load all events for the entire history of an aggregate
Each aggregate defines a snapshot trigger:
@Aggregate(snapshotTriggerDefinition = "courierSnapshotTriggerDefinition")- Feel free to configure a treshold (number of events) that should trigger the snapshot creation. This treshold is externalized as a property
axon.snapshot.trigger.treshold.courier
Generic subdomains
Other subdomains facilitate the business, but are not core to the business. In general, these types of pieces can be purchased from a vendor or outsourced. Those are generic subdomains:
Event sourcing is probably not needed within your ‘generic subdomain’.
As Eric puts it into numbers, the ‘core domain’ should deliver about 20% of the total value of the entire system, be about 5% of the code base, and take about 80% of the effort.
Organisation vs encapsulation
When you make all types in your application public, the packages are simply an organisation mechanism (a grouping, like folders) rather than being used for encapsulation. Since public types can be used from anywhere in a codebase, you can effectively ignore the packages.
The way Java types are placed into packages (components) can actually make a huge difference to how accessible (or inaccessible) those types can be when Java’s access modifiers are applied appropriately. Bundling the types into a smaller number of packages allows for something a little more radical. Since there are fewer inter-package dependencies, you can start to restrict the access modifiers. Kotlin language doesn’t have ‘package’ modifier as Java has. It has ‘internal’ modifier which restricts accessiblity of the class to the whole module (compile unit, jar file…) which can hold many packages.
The goal (maybe it is a rule) is to bundle all of the functionality related to a single component into a single Java/Kotlin package, and restrict accessiblity of the classes to package, were possible.
For example, our Customer component classes are placed in one com.drestaurant.customer.domain package, with all classes marked as ‘internal’.
Public classes are placed in com.drestaurant.customer.domain.api and they are forming an API for this component. This API consist of commands and events.
As we have one maven module holding one package/component we are using Kotlin internal modifier as an encapsulation mechanism on the package level as well. This rule is handled by the compiler, which is very good, and we can achieve loose coupling and high cohesion effectively.
If you prefer to organize more packages/components into one maven module (maybe use single maven module for all components, and not multi maven module by component as we have now) you should use different encapsulation mechanism because Kotlin is lacking of package modifier.
We use an ArchUnit test to force ‘package’ scope of the Kotlin classes. This rule is handled on the Unit test level, which is not perfect, but still valuable.
Context Mapping
Bounded contexts (and teams that produce them) can be in different relationships:
- partnership (two contexts/teams succeed or fail together)
- customer-supplier (two teams in upstream/downstream relationship - upstream can succeed interdependently of downstream team)
- conformist (two teams in upstream/downstream relationship - upstream has no motivation to provide to downstream, and downstream team does not put effort in translation)
- shared kernel (sharing a part of the model - must be kept small)
- separate ways (cut them loose)
- anticorruption layer
You may be wondering how Domain Events can be consumed by another Bounded Context and not force that consuming Bounded Context into a Conformist relationship.
Consumers should not use the event types (e.g., classes) of an event publisher. Rather, they should depend only on the schema of the events, that is, their Published Language. This generally means that if the events are published as JSON, or perhaps a more economical object format, the consumer should consume the events by parsing them to obtain their data attributes. This rise complexity (consider consumer driven contracts testing), but enables loose coupling.
Our demo application demonstrate conformist pattern, as we are using strongly typed events.
As our application evolve from monolithic to microservices we should consider diverging from conformist and converging to customer-supplier bounded context relationship depending only on the schema of the events (with consumer driven contracts included).